3.3 Estructuras de datos
La mayoría de las bases datos contienen más de una variable de acuerdo a una cantidad de observaciones y no necesariamente los datos tiene que ser del mismo tipo de dato. En caso de que se deseara ejecutar algún algoritmo para la manipulación de estos, bien se podría tomar cada variable como un vector y ser ingeniosos y cuidadosos para relacionar todos esos vectores y obtener resultados útiles. Esta manera de trabajar no es eficiente ni la más recomendable, ya que se dedicará una mayor cantidad de tiempo a la programación y una menor a la obtención de resultados.
Existen muchas estructuras de datos y aunque todas pueden ser adaptadas a un lenguaje de programación, cada lenguaje tiene estructuras básicas para trabajar. Java tiene los arreglos y otro tipo de estructuras en ciertas librerías como listas, pilas y colas. Python tiene diccionarios y mediante la librería pandas utiliza marcos de datos (data frames). En el caso de R también se tienen esta última y otras más. La siguiente imagen resume las estructuras de datos en R.
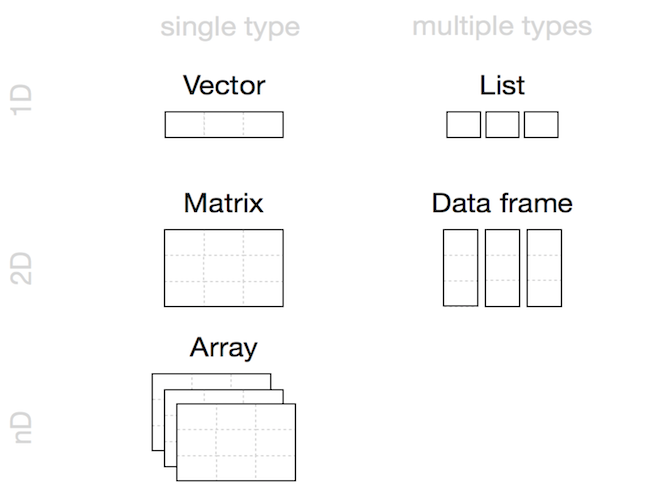
Fuente: Hands-On Programming with R.
3.3.1 Vectores
Ya se ha tratado esta estructura pero faltan algunas cosas por ver.
- ¿Qué sucede cuando se ejecuta el siguiente código?
c(TRUE, 1,2,5,9.4).
Lo que sucede aquí es llamado coercion. En otros lenguajes de programación esto puede ser entendido como promoción y casteo, pero en este caso no es necesario hacer una declaración explicita del tipo de dato al que se desea convertir. La coerción se aplicará en cualquier estructura que use vectores.
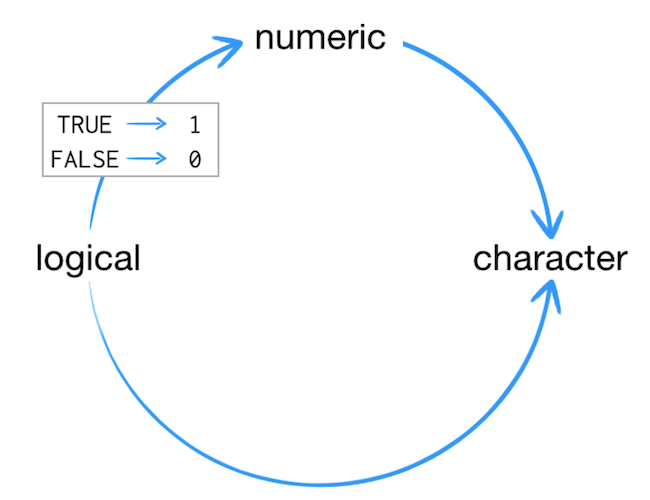
Fuente: Hands-On Programming with R.
En la imagen anterior quedan claras las reglas que se tienen al hacer coerción. Por ejemplo, ¿Qué tipo de vector resultará en las siguientes instrucciones?
c("1", "2", 3)
c(4, "a", TRUE)
4 == "4"
1 < FALSE
"a" != FALSEAsí como se tienen funciones para verificar si un vector es de algún tipo, también es fácil recordar las funciones para cambiar un tipo de dato a otro; en este caso en lugar de comenzar con el prefijo is., se usará as. dando así las funciones as.double(), as.character, etc. Y esto no se limita a los vectores atómicos, ya que ciertas estructuras se pueden convertir a otras, aunque hay que tener en cuenta que ciertos atributos pueden eliminarse o que en ciertas ocasiones no será posible hacer la conversión.
Finalmente, al tener una estructura que contiene datos, es de esperar una sintaxis para obtener los elementos que la componen. En el caso de los vectores, la obtención de los elementos interiores se puede hacer mediante de diferentes maneras.
- Posición de un elemento:
(1:10)[[3]].(1:10)[3] - ¿Cuál es la diferencia entre
[[o[? Hint:?'[['. - Posición mediante un vector:
(1:10)[seq(1, 10, by = 2)];(1:10)[c(4,5)]. - Mediante filtros (subsetting)
(1:10)[(1:10)<4]. - Con nombres.
Un atributo que tienen los vectores es llamado names, el cual otorga un nombre a cada uno de los elementos interiores del vector.
vec_altura <- c(1.50, 1.60, 1.72, 1.55)
names(vec_altura) <- c("José", "Raúl", "Cecilia", "Camila")
vec_altura[["José"]][1] 1.5Por último, véase la aplicación tablas de búsqueda (Character subsetting) que otorga el subsetting en los vectores.
datos_frutas <- c("M", "Ma", "S", "M", "S", "Ma")
frutas <- c(M = "Manzana", Ma = "Mango", S = "Sandía")
frutas[datos_frutas] M Ma S M S Ma
"Manzana" "Mango" "Sandía" "Manzana" "Sandía" "Mango" unname(frutas[datos_frutas])[1] "Manzana" "Mango" "Sandía" "Manzana" "Sandía" "Mango" 3.3.2 Listas
Las listas son una estructura de datos muy útil por la forma en la que esta codificada, ya que esta nos ayuda a tener vectores en su interior y de diferentes tipos. Comúnmente se le conoce a las listas como vectores recursivos, ya que una lista puede contener listas en su interior (las listas son otro tipo de objeto así que no hay restricciones para hacer listas de listas). Como bien indica una de las imágenes anteriores, las listas tienen una dimensión, lo cual no se debe confundir con su longitud, la cual es la cantidad de elementos que esta contiene.
- El constructor por defecto es
list()y el tipo eslist. - Se pueden dar nombres a los elementos de las listas de la siguiente manera:
list("nombre" = datos) - No es necesario dar nombres para construir una lista
list(c(1,5), 1:10)[[1]]
[1] 1 5
[[2]]
[1] 1 2 3 4 5 6 7 8 9 10- Los elementos internos de una lista, al tener la posibilidad de ser diferentes, se pueden tener diferentes tamaños.
list(1:2, 1:10, letters[1:5])[[1]]
[1] 1 2
[[2]]
[1] 1 2 3 4 5 6 7 8 9 10
[[3]]
[1] "a" "b" "c" "d" "e"- Se tiene la función
is.list()yas.list()como cualquier otra estructura de datos en R. - Esta sería una forma de hacer una lista de listas
list(list("a","b", "c"), "numeros" = list(1:10,1:5, 10:20, -3:-5))[[1]]
[[1]][[1]]
[1] "a"
[[1]][[2]]
[1] "b"
[[1]][[3]]
[1] "c"
$numeros
$numeros[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
$numeros[[2]]
[1] 1 2 3 4 5
$numeros[[3]]
[1] 10 11 12 13 14 15 16 17 18 19 20
$numeros[[4]]
[1] -3 -4 -5Como las listas y los vectores son de una dimensión, estas estructuras tiene algunas características en común; ambas tienen una longitud y puede determinarse su tipo (typeof(vector(), typeof(list())). Además en ambas se les puede asignar nombres y otros atributos que se deseen para dar meta data a las estructuras. Para dar un nuevo atributo se puede usar la función attr().
lista_1 <- list("numeros" = c(1,2,3), "letras" = c("a","b","c"), "ambos" = c(1,2,"3", "4"))
attr(lista_1, "meta") <- "Más datos"
attr(vec_altura, "atributo_extra") <- "Más datos"
attributes(lista_1)$names
[1] "numeros" "letras" "ambos"
$meta
[1] "Más datos"attributes(vec_altura)$names
[1] "José" "Raúl" "Cecilia" "Camila"
$atributo_extra
[1] "Más datos"Al usar la función structure(), no es necesario usar la función attr() para agregar un nuevo atributo.
structure(seq(2,20, by = 2), paridad = "Pares") [1] 2 4 6 8 10 12 14 16 18 20
attr(,"paridad")
[1] "Pares"- ¿Qué sucede al hacer
structure(seq(2,20, by = 2), comment = "Pares")?
En general, para ver la composición de una estructura, La función str() es de grán utilidad ya que dará de manera resumida esta composición.
str(vec_altura) Named num [1:4] 1.5 1.6 1.72 1.55
- attr(*, "names")= chr [1:4] "José" "Raúl" "Cecilia" "Camila"
- attr(*, "atributo_extra")= chr "Más datos"str(lista_1)List of 3
$ numeros: num [1:3] 1 2 3
$ letras : chr [1:3] "a" "b" "c"
$ ambos : chr [1:4] "1" "2" "3" "4"
- attr(*, "meta")= chr "Más datos"Al poder acceder a los elementos de un vector o una lista, es sencillo cambiar el contenido de estos.
lista_1[["numeros"]] <- 2:4
lista_1$numeros
[1] 2 3 4
$letras
[1] "a" "b" "c"
$ambos
[1] "1" "2" "3" "4"
attr(,"meta")
[1] "Más datos"vec_altura[vec_altura<1.60] <- 1.50
vec_altura José Raúl Cecilia Camila
1.50 1.60 1.72 1.50
attr(,"atributo_extra")
[1] "Más datos"- El acceso a una lista puede ser de diferentes maneras
- Mediante el nombre del elemento:
lista_1[["numeros"]]olista_1$numeros. - Mediante la posición:
lista[[1]] - ¿Cuál es la diferencia entre
lista[[1]]ylista[1]?
- Mediante el nombre del elemento:
lista_1$ambos <- NULL
str(lista_1)List of 2
$ numeros: int [1:3] 2 3 4
$ letras : chr [1:3] "a" "b" "c"
- attr(*, "meta")= chr "Más datos"Lo anterior es un ejemplo de como borrar elementos de una lista.
- ¿Esto se puede hacer con un vector? ¿Si, no, porqué? 🤷
- Hint: ¿Qué sucede al hacer lo siguiente?
v <- 1:10;v[5] <- "5".
- Hint: ¿Qué sucede al hacer lo siguiente?
- ¿Es posible convertir una lista a un vector? Sí, pero ¿Por qué
as.vector(lista_1)sigue siendo una lista? - ¿Qué hace
unlist()? - ¿Qué atributos permanecen al hacer hacer una correcta conversión?
3.3.3 Arreglos
Todos aquellos que ya hayan tenido algún acercamiento con algún lenguaje de programación como Java, C, C++, Python, etc. conocen lo importante que pueden ser los arreglos, los cuales son una colección de elementos con ciertas posiciones. Además del simple hecho de poder almacenar elementos en un solo objeto, es de gran importancia lograr manejar matrices para realizar distintas operaciones y obtener ciertos resultados para diferentes problemas del ámbito científico.
Como bien se indica en el diagrama donde se presentan las diferentes estructuras de datos que tenemos disponibles en R, las matrices y los arreglos solo aceptan un sólo tipo de dato como los vectores. De hecho, véase que internamente, los constructores de una matriz y un arreglo (matrix() y array()) tienen que convertir, en caso de que sea necesario, el input a un vector.
#matrix():
.
.
if (is.object(data) || !is.atomic(data))
data <- as.vector(data)
.
.
}
#array():
.
.
data <- as.vector(data)
.
.
}Por lo que una matriz y un array los podemos considerar vectores, solo que con diferentes dimensiones. Solo para aclarar, al momento de ingresar listas o matrices a estos constructores, todo será llevado a vectores y se realizará, en caso de ser necesario, coerción y reciclaje.
- ¿Qué sucede al ejecutar
matrix(list(1,2,3,4))?
Considérese los siguientes puntos cuando se desea construir una matriz o cuando se trabaje con ellas.
Se tienen las correspondientes funciones
is.matrix()yas.matrix().El constructor
matrix()en su primer argumento solicita los datos los cuales pueden ser cualquier vector.
matrix(1:10) [,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
[5,] 5
[6,] 6
[7,] 7
[8,] 8
[9,] 9
[10,] 10- Automáticamente
matrix()dispone de sus elementos en forma columnar. - El constructor de las matrices permite agregar el número de renglones y columnas.
matrix(1:10, nrow = 5, ncol = 2) [,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10- La matriz se rellena en base a columnas, pero esto puede ser modificado. ¿Cómo?
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
[4,] 7 8
[5,] 9 10- Se puede acceder a los elementos de una matriz de manera análoga a los vectores y listas solo que considerando las dos dimensiones.
matrix(1:10, nrow = 5, ncol = 2, byrow = TRUE)[1,1][1] 1- Si no se indica algún valor, o ambos, para alguna dimensión, R entenderá que se desea abarcar toda esa dimensión.
matrix(1:10, nrow = 5, ncol = 2, byrow = TRUE)[,2][1] 2 4 6 8 10- También es posible acceder mediante nombres en una matriz. En este caso existe la distinción entre renglones y columnas, y las correspondientes funciones para obtener y modificar los nombres son
rownames()ycolnames().
m <- matrix(1:10, nrow = 5, ncol = 2, byrow = TRUE)
rownames(m) <- paste("Row", 1:5)
colnames(m) <- paste("Column", 1:2)
m Column 1 Column 2
Row 1 1 2
Row 2 3 4
Row 3 5 6
Row 4 7 8
Row 5 9 10m["Row 5","Column 2"][1] 10- Al igual que en los vectores, se puede acceder mediante vectores booleanos o expresiones que resulten en vectores booleanos.
m[1,m[1,]<2][1] 1- El equivalente de
length()en vectores, se divide ennrow()yncol(); además de la funcióndim()para obtener ambos resultados
cat("nrow: ",nrow(m), "\nncol: ",ncol(m), "\ndim:", "c(",dim(m),")")nrow: 5
ncol: 2
dim: c( 5 2 )- La función
dim()se puede usar para modificar la estructura de una matriz; aunque esto puede ocasionar una pérdida de atributos.
dim(m) <- c(2,5)
m [,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 4 8
[2,] 3 7 2 6 10- La función anterior puede usarse también con vectores. Al hacer esto ¿El resultado es una matriz? Compruébelo.
vec <- 1:10
dim(vec) <- c(5,2)
vec [,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10- Con las funciones
cbin()yrbind()se pueden unir matrices por columna o por renglón.
first <- 1:10
second <- 2:11
cbind(first, second) first second
[1,] 1 2
[2,] 2 3
[3,] 3 4
[4,] 4 5
[5,] 5 6
[6,] 6 7
[7,] 7 8
[8,] 8 9
[9,] 9 10
[10,] 10 11Las matrices son de uso recurrente en el álgebra lineal, por lo que se desearía realizar algunas operaciones básicas entre ellas; R proporciona estas así como algunas funciones importantes. Supongamos que \(\mathcal{A}\) y \(\mathcal{B}\) son matrices definidas en R.
- Operaciones básicas
- Adición:\(\mathcal{A}\)
+\(\mathcal{B}\). - Sustracción: \(\mathcal{A}\)
-\(\mathcal{B}\). - Multiplicación por un escalar: \(c\)
*\(\mathcal{A}\). - Producto matricial: \(\mathcal{A}\)
%*%\(\mathcal{B}\).
- Adición:\(\mathcal{A}\)
- Funciones básicas
- Transpuesta:
t(). - Diagonal:
diag(). Devuelve la diagonal de una matriz o crea una matriz diagonal. - Determinante:
det(). - Inversa:
solve().solve()también resuelve un sistema de ecuaciones dado. - Varianza:
var(). - Vectores y valores propios:
eigen().
- Transpuesta:
Hay que tener en cuenta la teoría sobre estas operaciones o funciones ya que será relevante las dimensiones de las matrices; por ejemplo si las matrices son cuadradas para obtener el determinante o la inversa o si las dimensiones de \(\mathcal{A}\) y \(\mathcal{B}\) son adecuadas para aplicar, por ejemplo, la multiplicación entre ellas. Para ver algunas otras funciones que se pueden aplicar en las matrices véase los enlaces 1 y 2.
Finalmente, cuando se desea crear un arreglo con un número mayor de dimensiones, se puede utilizar el constructor array() donde se pueden indicar las dimensiones como parámetro, por ejemplo array(1:16, c(2,2,4)). Las operaciones básicas funcionan correctamente en este tipo de estructura pero la mayoría de las funciones, al menos todas las mencionadas, no trabajan bien al tratar con arreglos ya que las funciones anteriores solicitan arreglos de dos dimensiones.
- ¿Una matriz es un arreglo y un arreglo es una matriz?
3.3.4 Data Frames
Al trabajar con matrices se debe estar consciente de que cada uno de sus elementos es de un solo tipo, lo cual puede resultar problemático al tratar con una base de datos donde se tengan datos numéricos y categóricos o incluso cuando se desee agregar una columna de otro tipo de objetos como lo son las gráficas. Aquella estructura de datos que dos dimensiones que acepta diferentes tipos de datos por columna se le llama Data Frame. La mayoría de las bases de datos se trabajan con un data frame y por convención a las columnas se les llama variables y a los renglones observaciones.
La construcción de un data frame se puede hacer mediante el constructor por defecto data.frame() donde el contenido de este es similar al de una lista, ya sea dando los nombres desde la creación o posteriormente. Por ejemplo:
data.frame(c1 = 1:5, c2 = letters[1:5], c3 = list(1,2,3,4,5), c4 = matrix(0,5,2)) c1 c2 c3.1 c3.2 c3.3 c3.4 c3.5 c4.1 c4.2
1 1 a 1 2 3 4 5 0 0
2 2 b 1 2 3 4 5 0 0
3 3 c 1 2 3 4 5 0 0
4 4 d 1 2 3 4 5 0 0
5 5 e 1 2 3 4 5 0 0Hay que notar lo siguiente del anterior ejemplo.
- Los vectores son tomados de manera columnar como en las matrices.
- Los caracteres son considerados como factores; esto puede cambiar modificando el parámetro
stringsAsFactorsdel constructor. - Por cada elemento de la lista se agrego una columna.
- Las matrices son tomadas con la misma estructura en cuanto a los renglones y columnas.
Estos puntos son considerados en cuenta cuando se desea convertir algún otro objeto en data frame con la función as.data.frame().
- Se debe ser cuidadoso con el número de observaciones en cada variable, ya que estos deben ser iguales, lo cual puede ser relevante al usar las funciones
rbind()ycbind()entre data frames. En general, estas funciones deben usarse si alguno de los objetos implicados es un data frame, en caso de que alguno no lo sea y ambos sean vectores, las funciones crearán primero una matriz aplicando coerción y dando problemas en la construcción del data frame.
El constructor de una data frame, data.frame(), es más robusto que el constructor de una matriz, matrix(), ya que aquí se deben mantener las estructuras en las columnas; por ejemplo una columna de listas no deben convertirse en una columna de números como en el caso de una matriz para una sola lista. Si se desea tener una columna de listas y no distribuir los elementos de la lista en las columnas de data frame, se puede utilizar la función I() la cual ayuda a tratar un objeto como el mismo y así no aplicarle algún tipo de transformación.
(df <- data.frame(numbers = 1:3, listas= I(list(num_list = 1:10,letras = letters,listas = list(1,2,3,4))))) numbers listas
num_list 1 1, 2, 3,....
letras 2 a, b, c,....
listas 3 1, 2, 3, 4Al igual que las listas, el acceso puede ser mediante los nombres y posición además de vectores booleanos, agregando el acceso que se aplica en las matrices.
df$listas$letras [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"df[["numbers"]][1] 1 2 3df[1,2]$num_list
[1] 1 2 3 4 5 6 7 8 9 10df[1,2]$num_list [1] 1 2 3 4 5 6 7 8 9 10df[2,c(typeof(df$numeros), typeof(df$listas))=="list"]$letras
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"- Es posible agregar nombres a los renglones de un data frame como en una matriz.
row.names(df) <- 1:3
df numbers listas
1 1 1, 2, 3,....
2 2 a, b, c,....
3 3 1, 2, 3, 4- ¿Qué sucede al usar la función
as.matrix()con el anterior data frame? - ¿Se puede cambiar la dimensión de un data frame como en una matriz usando la función
dim()? - ¿Se pueden aplicar operaciones básicas entre data frames? ¿Cuáles y en que caso?
No esta de más mencionar que hay otro tipo de objeto en R llamado expresiones. Estas son importantes al momento de desarrollar una función a un nivel más profesional. En este libro no se tratará dicho tema pero se puede estudiar a profundidad de esto en el libro Advance R. Aquí se deja un simple ejemplo de tal objeto.
x <- 3
y <- 2.5
z <- 1
exp <- expression(x/(y + exp(z)))Ejercicios
La siguiente instrucción genera un vector con valores numéricos y
NA:sample(c(1:20, rep(NA,15))). El anterior vector se debe guardar con el nombre de random_NA y Usando algún ciclo, determine cuantos valoresNAhay en random_NA.Utilizando los conocimientos de coerción, la función
sum()y lo que sea necesario, determinar cuantos valoresNAexisten en random_NA.Crea una función que, dado un vector, se determine la cantidad de valores perdidos en él.
Crear un función que, dado un número se cree una matriz que contenga solo ese número. El número de renglones y columnas debe también ser dado en los parámetros de la función.
Usando algún ciclo, crear una función llamada
suma_gaussen la que se tendrá que simular el proceso para la suma de los primeros \(n\) números en \(\mathbb{N}\). No se debe utilizar la formula de manera directa.Crear una matriz, sin tener que usar algún ciclo, de 0s y 1s alternados. Aquí un ejemplo
[,1] [,2] [,3] [,4]
[1,] 0 1 0 1
[2,] 1 0 1 0
[3,] 0 1 0 1
[4,] 1 0 1 0
[5,] 0 1 0 1 [,1] [,2] [,3] [,4] [,5]
[1,] 1 25 81 169 289
[2,] 4 36 100 196 324
[3,] 9 49 121 225 361
[4,] 16 64 144 256 400Crear un data frame con 5 variables y al menos 3 observaciones. La primera variable corresponderá a nombres de una persona, las demás representarán la edad, altura, peso y nacionalidad de cada individuo. Se puede usar la función
sample().En el anterior data frame, agregar una sexta variable que represente los videojuegos que tiene cada usuario. Los datos deben ser los siguientes:
list(juegos = c("Horizon-Zero-Dawn", "bloodborne")),list(juegos = c("Mario-Kart", "Mario Maker", "Mario Odyssey")),list(c("Halo", "Batman Arkham Knight", "Injustice")). Si hacen falta más datos, crearlos o replicar los ya dados.Crear un función que regrese una lista donde cada elemento de la lista tendrá el nombre de cada una de las estructuras y los tipos de datos ya vistos y su contenido será un vector booleano indicando si, de acuerdo al parámetro de la función, se es de alguna clase de las ya vistas. Por ejemplo, si se da como input una matriz de caracteres, la lista resultante en la posición
[["Matriz"]]y en[["Caracter"]]deben contener el valorTRUE.
[,1] [,2] [,3] [,4] [,5]
[1,] "a A" "e E" "i I" "m M" "q Q"
[2,] "b B" "f F" "j J" "n N" "r R"
[3,] "c C" "g G" "k K" "o O" "s S"
[4,] "d D" "h H" "l L" "p P" "t T"Del data frame del inciso 22, obtener mediante una expresión lógica las columnas, que de acuerdo al primer renglón, contengan valores menores a 150.
Crea una lista que contenga al menos cada una de las estructuras ya vistas.
Crear una función que, dadas dos matrices, se verifique si estas son aptas para aplicarles las operaciones fundamentales suma y sustracción y regresar dichos resultados en una lista; en caso de que sean aptas para la multiplicación agregar este resultado a la lista de retorno.
Crear un ciclo dentro de una función donde, de acuerdo a un data frame de entrada, y utilizando la primera observación del data frame, se determine el tipo de variable que contiene el data frame en cada columna. Finalmente todos los resultados deben ser devueltos en un vector.